Diyabet Tahmini Uygulaması: Lojistik Regresyon & ML
Kullanılan Veri Seti:
Kaggle «Diabetes prediction dataset» veri seti.
100000 satır veri
(Veri Seti: diabetes_prediction_dataset)
Veri seti alanları;
gender: Cinsiyet
age: Yaş
hypertension: Hipertansiyon
heart_disease: Kalp Hastalığı
smoking_history: Sigara Kullanma Geçmişi
bmi: Vücut Kitle İndeksi
HbA1c_level: HbA1c Seviyesi (Glikozile Hemoglobin Seviyesi)
blood_glucose_level: Kan Şeker Seviyesi
diabetes: Diyabet
Kullanılan Kütüphaneler;
pandas: Veri manipülasyonu ve analizi için kullanılır. Veri setini okuma, veri çerçeveleri oluşturma ve veri önişleme görevleri için esastır.
numpy: Sayısal hesaplamalar için kullanılır. Ayrıca matris işlemleri ve matematiksel fonksiyonların uygulanması için kullanılır.
sklearn (Scikit-learn): Makine öğrenimi algoritmalarını uygulamak için kullanılır. Ayrıca veri ön işleme, model seçimi ve değerlendirme için gerekli araçları da içerir.
sklearn.model_selection: Veri setini eğitim ve test setlerine ayırmak için kullanılır.
sklearn.linear_model: Lojistik regresyon gibi doğrusal modelleri içerir.
sklearn.metrics: Model performans metriklerini hesaplamak için kullanılır.
matplotlib: Veri görselleştirmesi ve grafik çizimi için kullanılır.
seaborn: Matplotlib temel alınarak oluşturulmuş bir veri görselleştirme kütüphanesidir. Daha estetik ve bilgilendirici grafikler oluşturmak için kullanılır.
Python uygulama kodu;
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, roc_curve, auc, accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv("diabetes_prediction_dataset.csv")
data = pd.get_dummies(data, columns=["gender", "smoking_history"], drop_first=True)
X = data.drop("diabetes", axis=1)
y = data["diabetes"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = LogisticRegression(max_iter=1000) model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
roc_auc = roc_auc_score(y_test, model.predict_proba(X_test)[:, 1])
print("Accuracy (Doğruluk):", accuracy)
print("Precision (Kesinlik):", precision)
print("Recall (Duyarlılık):", recall)
print("F1 Score:", f1)
print("ROC AUC Score (ROC Eğrisi):", roc_auc)
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt="d", cmap='Blues')
class_names = [0, 1]
tick_marks = np.arange(len(class_names))
plt.xticks(tick_marks, class_names)
plt.yticks(tick_marks, class_names)
plt.text(0,0, "Doğru Negatif", va='center', ha='center')
plt.text(0,1, "Yanlış Pozitif", va='center', ha='center')
plt.text(1,0, "Yanlış Negatif", va='center', ha='center')
plt.text(1,1, "Doğru Pozitif", va='center', ha='center')
plt.title('Confusion Matrix')
plt.ylabel('True Label')
plt.xlabel('Predicted Label')
plt.show()
y_pred_proba = model.predict_proba(X_test)[::,1]
fpr, tpr, _ = roc_curve(y_test, y_pred_proba)
auc = auc(fpr, tpr)
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, label="AUC="+str(auc))
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend(loc=4)
plt.show()
Sonuçların Çıktısı;
Accuracy (Doğruluk): 0.959
Precision (Kesinlik): 0.8633387888707038
Recall (Duyarlılık): 0.6176814988290398
F1 Score: 0.720136518771331
ROC AUC Score (ROC Eğrisi): 0.9616922634432529
Sonuçların Yorumlanması;
Doğruluk: %95.9. Bu, modelimizin test veri seti üzerinde tahminlerin yaklaşık %95.9’unu doğru yaptığı anlamına gelir. Bu oldukça yüksek bir orandır ve genellikle modelimizin iyi çalıştığını gösterir. Ancak dikkatli olmalıyız, çünkü eğer sınıflar dengesiz dağılmış olabilir (örn. çok fazla negatif örnek ve çok az pozitif örneğimiz var) doğruluk yanıltıcı olabilir.
Kesinlik: %86.3. Modelimizin tahmin ettiği pozitif vakaların %86.3’ü gerçekten pozitif. Bu oran da oldukça yüksek ve modelimizin yanlış pozitif tahminler yapma olasılığının düşük olduğunu gösterir.
Duyarlılık: %61.8. Gerçek pozitif vakaların %61.8’i model tarafından doğru bir şekilde tespit edilmiş. Bu oran, kesinlikle kıyaslandığında biraz daha düşüktür, bu da modelimizin bazı pozitif vakaları kaçırdığı anlamına gelir.
F1 Skoru: %72. Modelimizin kesinlik ve duyarlılık arasında orta düzeyde bir dengeye sahip olduğunu gösterir. Bu, modelimizin yanlış pozitifleri azaltırken bazı gerçek pozitifleri kaçırdığı anlamına gelir.
ROC AUC: %96.2. Bu değer, modelimizin genel sınıflandırma performansının mükemmel olduğunu gösterir. AUC, bir sınıflandırma modelinin rastgele seçilen bir pozitif örneği rastgele seçilen bir negatif örneğinden daha yüksek bir olasılığa sahip olduğunu doğru bir şekilde sıralama olasılığını gösterir.
Yorum:
Genel olarak modelimizin iyi bir performans sergilediğini söyleyebiliriz. ROC AUC ve Doğruluk değerleri oldukça yüksek. Ancak, duyarlılık değeri kesinlikle kıyaslandığında biraz düşük, bu da modelimizin bazı gerçek pozitif vakaları kaçırdığını gösteriyor. Bu, tıbbi testlerde özellikle önemlidir, çünkü gerçek pozitif vakaların (hastaların) kaçırılması istenmeyen bir durumdur. Modelimizin yanlış negatifleri (gerçekte pozitif olan ama negatif olarak tahmin edilen vakalar) azaltma yeteneğini artırmamız gerekebilir. Bunun için model hiperparametrelerini ayarlamayı veya farklı öznitelik mühendisliği teknikleri uygulamayı düşünebiliriz.
Karışıklık Matrisi Çıktısı
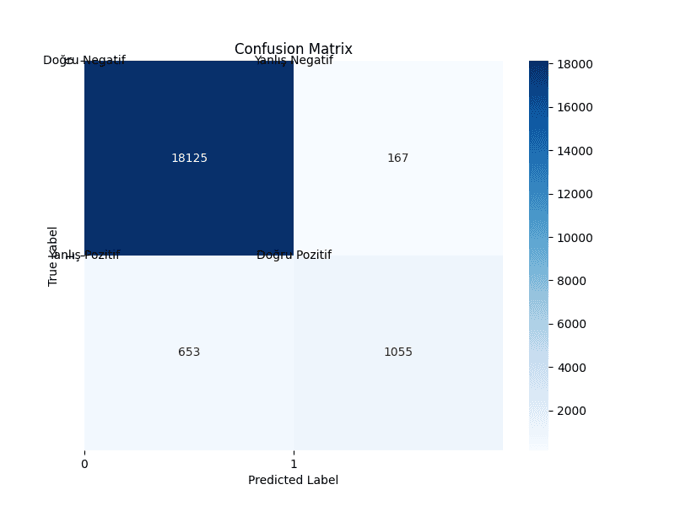
DN (Doğru Negatif): Gerçekte 0 olan ve model tarafından 0 olarak tahmin edilen örneklerin sayısı.
DP (Doğru Pozitif): Gerçekte 1 olan ve model tarafından 1 olarak tahmin edilen örneklerin sayısı.
YN (Yanlış Negatif): Gerçekte 1 olan fakat model tarafından 0 olarak tahmin edilen örneklerin sayısı.
YP (Yanlış Pozitif): Gerçekte 0 olan fakat model tarafından 1 olarak tahmin edilen örneklerin sayısı.
Doğru Tahminler: Model, genellikle doğru tahminlerde bulunuyor. Özellikle gerçekte 0 olan verileri tahmin ederken oldukça başarılı.
Hassasiyet (Recall/Duyarlılık) ile İlgili Sorun: Model, gerçekte 1 olan verilerin bir kısmını yanlışlıkla 0 olarak tahmin ediyor (167 adet YN). Bu, modelin bazı diyabet vakalarını kaçırdığı anlamına gelir.
Yanlış Alarm (False Alarm) Oranı: Model, gerçekte diyabeti olmayan 653 kişiyi yanlışlıkla diyabetli olarak sınıflandırmış. Bu, modelin bazen aşırı duyarlı olabileceğini gösteriyor.
Diyabeti Doğru Tespit Etme: Model, gerçekten diyabeti olan 1055 kişiyi doğru bir şekilde tespit etmiş.
ROC Eğrisi Çıktısı
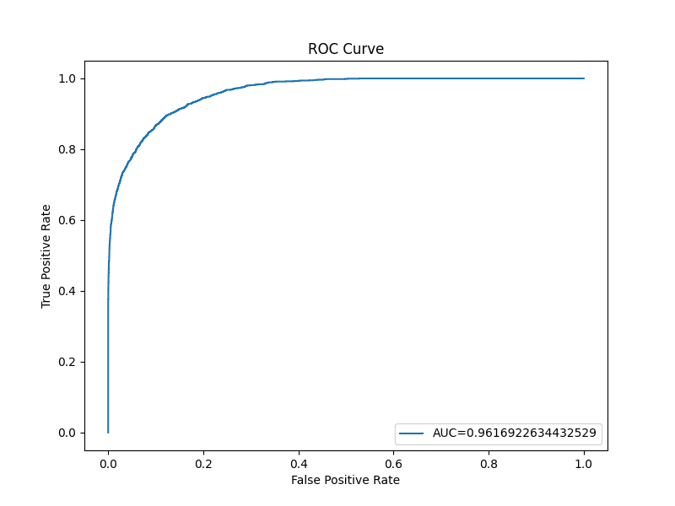
ROC Eğrisi, sınıflandırıcıların performansını değerlendirmek için kullanılan grafiksel bir yöntemdir. Bu eğri, Doğru Pozitif Oranı (Duyarlılık) ile Yanlış Pozitif Oranı arasındaki ilişkiyi gösterir.
True Positive Rate (TPR) – Duyarlılık (Hassasiyet): Doğru pozitif olarak sınıflandırılan örneklerin gerçekten pozitif olan örnekler arasındaki oranıdır.
True Positive Rate = DP/(DP+YN)
False Positive Rate (FPR) – Yanlış Pozitif Oranı: Yanlış pozitif olarak sınıflandırılan örneklerin gerçekte negatif olan örnekler arasındaki oranıdır.
False Positive Rate = YP/(YP+DN)
Eğer bir ROC eğrisi sol üst köşeye yakınsa (yani eğri y eksenine yakın), modelin performansı iyidir. Eğer eğri, y=x çizgisine yakınsa (45 derecelik çizgi), modelin performansı rastgele tahmin etmekten farksızdır.
ROC AUC (Area Under the Curve) Skoru, ROC eğrisinin altındaki alanı temsil eder ve sınıflandırıcının performansını özetleyen tek bir değerdir. ROC AUC skoru 1’e yakın olduğunda, modelin performansı mükemmeldir. Eğer ROC AUC skoru 0.5’e yakınsa, model rastgele tahmin etmekten farksızdır.
Yüksek Lisans Derslerimden Biyoistatistik Uygulamaları dersinde hazırladığım Özel Konu Projemi paylaştım. Dersi aldığım Prof. Dr. Filiz KARAMAN hocama saygı ve teşekkürlerimle.


